【Jupyter Notebook】基礎編(基本操作コードの作成方法・Markdown・数式)

こんにちは。今日はJupyterNotebookの基礎編です
対象
※Anacondaをインストールしていない方はそちらから始めてください。
Jupyter Notebookでpythonを走らせることができ、コードを逐一確認できるので利便性が高いです。
基本操作
JupyterNotebookを開くところから、コードを実行し、そのファイルを閉じるところまでです。
Jupyter Notebookを開く
Anacondaを開いたら、JupyterNotebookを押しましょう。するとブラウザにて開かれます。

ファイルを作成
コードを作成して走らせてみましょう。
まずはコードを作成するフォルダに移動しましょう。例えばDocument>Study>Code

移動をしたら、右上のNew>Python3をクリックします。
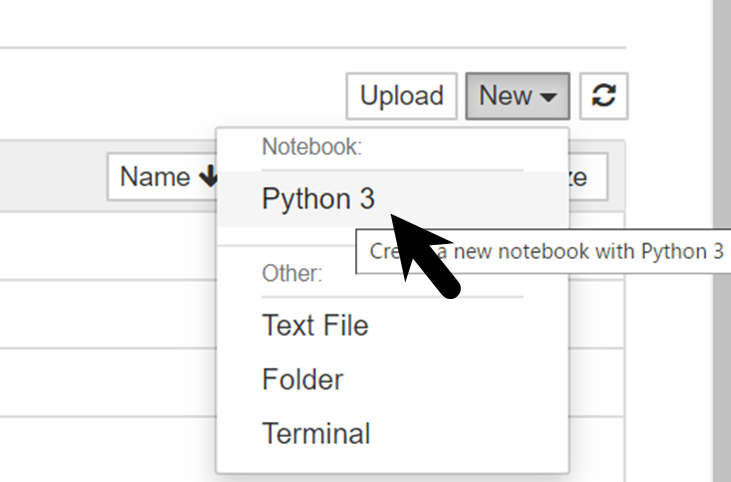
ファイル名変更
新しいファイルが作成されるので、ファイル名を変更しましょう。
Untitledをクリックして編集します。

コードの実行
コードを実行してみましょう
実行は、[Shift]+[enter] でできます。

カネルを閉じる
ファイルで作業が終わったら、×でタブを閉じるのではなく、以下の作業をしましょう。
これを押すことで、カネルが停止されます。

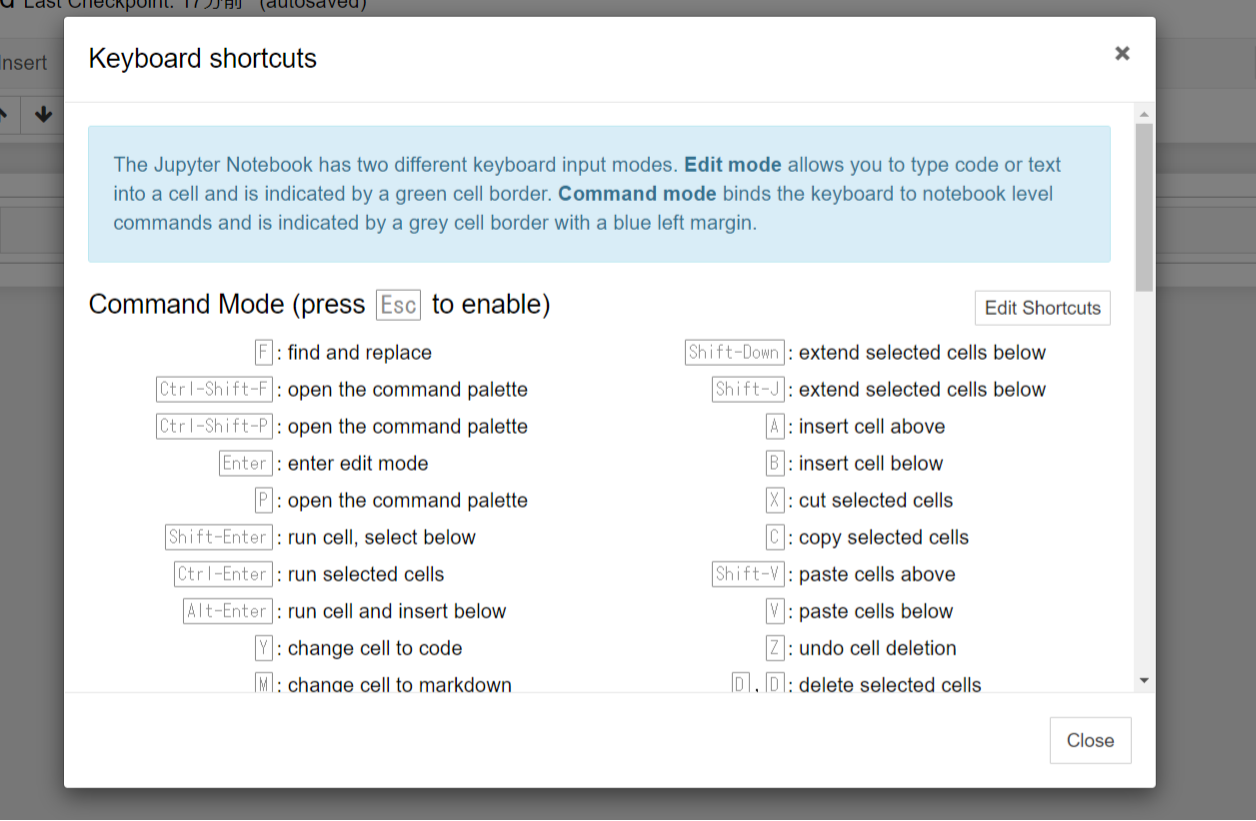
パネル詳細
パネルの詳細を載せます。使い方は以下にメモしましたが、実際に使ってみて挙動を見るのが良いと思います。それぞれ試してみてください。
その際はいくつかコードを書いておくとよくわかると思います。(1+1とかコードはなんでもOK)

よく使うコマンド
コマンドは作業効率を上げるのに役に立ちます。以下によく使うコマンドを載せますが、[esc]+[h]でさらに詳細を確認できます。
|
コマンド |
できること |
|
[Shift]+[enter] |
コードの実行 |
|
[Ctrl]+[s] |
セーブ |
|
[Ctrl]+[c] |
コピー |
|
[Ctrl]+[v] |
貼り付け |
|
[Ctrl]+[z] |
操作を1つ戻す |
|
[Ctrl]+[y] |
操作を1つ進める |
|
[Esc]+[m] |
モードをMarkdownに(メモ用) |
|
[Esc]+[z] |
消えてしまったコードを行ごと戻す |
Markdown
Markdownはコードだらけのファイルの見栄えを向上させ、後々ファイルを開いたときに編集した日の状況を理解できます。
[Esc]+[m]あるいはパネルを[Markdown]にすることでMarkdownモードに変更されます。
セクション
Markdownでセクション区切りを入れるとコードが見やすくなります。
コード
# セクション
## セクション
### セクション
#### セクション
セクション

リスト作成
作成予定のコードなどをリストにして残しておくことができます
※改行する際は必ず後ろに半角2つ入れてください。
コード
# CodeFlow
- Daily mean
- Calculation
- Graph
- Monthly mean
- Calculation
- Graph

作成予定のコードは番号や文字にすることも可能です。
※改行する際は必ず後ろに半角2つ入れてください。
コード
# CodeFlow
1. List
1. list
2. list
1. List
1. list
2. list

数式
Markdownでは数式を残しておくことができます。
書き方はLatex(ラテフ)を参照してください。
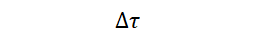
コード
$\Delta\tau$
コード
$\overline{x}=\frac{1}{n}\sum_{i=1}^{n} x_{i}$
それでは🌏
最終更新日
2021/1/2
【NumPy】Python NumPy基礎編(配列:結合)

こんにちは
今日はNumPyの基本的な使用方法について話していきたいと思います!
できること
など・・・
Numpyの使い方になれていない方は、まずはこちらの記事をご覧ください。
ベクトルの結合
まずはベクトルの結合です。以下のベクトルを例とします。

v = np.arange(5)
u = np.arange(0, 6, 2)
np.append()
np.append()を使えば簡単に右側から結合することができます。

np.append(v, u)
>>>array([0, 1, 2, 3, 4, 0, 2, 4])
行列の結合
2次元配列
次に行列の結合です。以下の行列を例とします。
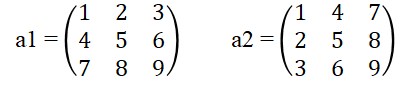
a1 = a
a2 = a.T
print(a1)
print(a2)
>>>[[1 2 3]
[4 5 6]
[7 8 9]]
>>>[[1 4 7]
[2 5 8]
[3 6 9]]
np.append()
ベクトルと同様に行列にもnp.append()を適用することができます。
しかしながら、結合の際にn×m行列からサイズがn・mのベクトルになります。
np.append(a1,a2)
>>>array([1, 2, 3, 4, 5, 6, 7, 8, 9, 1, 4, 7, 2, 5, 8, 3, 6, 9])
np.vstack()
vstack()は行列を縦方向に結合することができます。

np.vstack((a1,a2))
>>>array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
[1, 4, 7],
[2, 5, 8],
[3, 6, 9]])
np.hstack()
np.hstackは行列を横方向に結合することができます。

np.hstack((a1,a2))
>>>
array([[1, 2, 3, 1, 4, 7],
[4, 5, 6, 2, 5, 8],
[7, 8, 9, 3, 6, 9]])
3次元配列
最後に3次元配列です。
例えば、地球惑星科学科では全球のモデルや観測データで多次元の配列を多く活用します
今回は例として、以下のように行列を作成しました。

b1 = np.arange(3*3*3).reshape(3,3,3)
b1
>>>array([[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8]],
[[ 9, 10, 11],
[12, 13, 14],
[15, 16, 17]],
[[18, 19, 20],
[21, 22, 23],
[24, 25, 26]]])
np.vstack()
np.vstack()のvはverticallyを意味します。したがって、例に従うと時間軸方向に結合ができます。

np.vstack((b1,b1))
>>>array([[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8]],
[[ 9, 10, 11],
[12, 13, 14],
[15, 16, 17]],
[[18, 19, 20],
[21, 22, 23],
[24, 25, 26]],
[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8]],
[[ 9, 10, 11],
[12, 13, 14],
[15, 16, 17]],
[[18, 19, 20],
[21, 22, 23],
[24, 25, 26]]])
np.hstack()
np.vstack()のhはhorizontallyを意味します。したがって、例に従うと水平軸方向に結合ができます。

np.hstack((b1,b1))
>>>array([[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8]],
[[ 9, 10, 11],
[12, 13, 14],
[15, 16, 17],
[ 9, 10, 11],
[12, 13, 14],
[15, 16, 17]],
[[18, 19, 20],
[21, 22, 23],
[24, 25, 26],
[18, 19, 20],
[21, 22, 23],
[24, 25, 26]]])それでは🌏
最終更新日
2021/1/1
【Numpy】Python NumPy基礎編(配列:作成・リストから配列(逆も))

こんにちは
今日はNumPyの基本的な使用方法について話していきたいと思います!
配列:作成
- 連番配列を作成
- 行列配列を作成
- 同じ値の配列を作成
配列作成
まずは配列の作成です。配列の作成は様々な目的があると思います。
今回は、
- ベクトル・n×m行列の作成
- 同じ値の配列作成ーすべて0・すべて任意の値・すべてnan
を紹介します。
np.arange()
np.arange()では連番のベクトルが作成できます。
np.arange(配列のサイズ)
もしくは
np.arange(開始の数字, 終了の数字, 間隔)
で表されます。
np.arange(9)
>>>array([0, 1, 2, 3, 4, 5, 6, 7, 8])
np.arange(0, 10, 2)
>>>array([0, 2, 4, 6, 8])
np.arange()で行列を作成したい場合は、後ろに.reshape(n×m)をつけ足します。
np.arange(9).reshape(3,3)
>>>array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
np.zeros_like()とnp.zeros()
np.zeros_like()とnp.zeros()はどちらとも0の配列を返しますが、
前者は元の配列を0に変えるもの、後者は0の配列を新しく作るものです

x = np.arange(0, 10, 2)
np.zeros_like(x)
>>>[0 0 0 0 0]
print(np.zeros(5))
print(np.zeros((2,5)))
>>>[0. 0. 0. 0. 0.]
>>>[[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]]※行列はかっこを2つ付けることに注意してください。
np.full_like()
np.full_like()では任意の数字の配列を作成することが可能です。
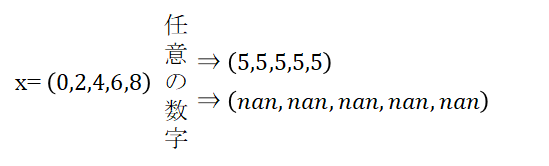
任意の数字を第2引数に渡す
np.full_like(x, 5)
>>>array([5, 5, 5, 5, 5])nanにしたい場合は必ずdtype=np.doubleに指定
print(np.full_like(v, np.nan))
print(np.full_like(v, np.nan, dtype=np.double)) # dtypeが必要
>>>[-2147483648 -2147483648 -2147483648 -2147483648 -2147483648]
>>>[nan nan nan nan nan]
配列(array)⇄リスト(list)
配列とリストは混同しやすいです。リストと同じように配列を作業しようとするとエラーが出たりするため、それぞれの型変更の方法を覚えておくと良いでしょう
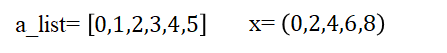
a_list = [0,1,2,3,4,5]
x = np.arange(0, 10, 2)リスト⇒配列「np.array()」
np.array(a_list)
>>>array([0, 1, 2, 3, 4, 5])
配列⇒リスト「np.tolist()」
x.tolist()
>>>[0, 2, 4, 6, 8]
それでは🌏
最終更新日
2021/01/01
【NumPy】Python NumPy基礎編(演算: ベクトル・行列)

こんにちは
今日はNumPyの基本的な使用方法について話していきたいと思います!
できること
など・・・
インポート
まずはモジュールをインポートします。
※numpyをインストールしていない場合はインストールしましょう⇓
【NumPy初心者必見】NumPyのインストール方法まとめました! | 侍エンジニア塾ブログ(Samurai Blog) - プログラミング入門者向けサイト
慣習的にnumpyはnpとします。
import numpy as np
多次元配列
多次元配列とはベクトルと行列のことです。
np.array(ベクトルor行列)
ベクトルの表記と行列の書き方に注意してください。
ベクトル
np.array([数字列])
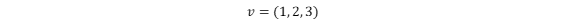
v = np.array([1, 2, 3])
v
>>>array([1, 2, 3])行列
行列は同じ行を[ ]でくくって、列はカンマで繋げます。
np.array([数字列],
[数字列],・・・)
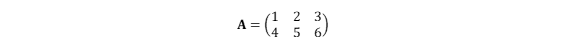
a = np.array([[1, 2, 3],
[4, 5, 6]])
a
>>>array([[1, 2, 3],
[4, 5, 6]])
配列の形・次元・要素数
配列の形は、.shape
次元は、.ndim
要素数は、.size
で確認できます。
print(a.shape)
print(a.ndim)
print(a.size)
>>>(2,3)
>>>2
>>>6
ベクトル・行列計算
ベクトルと行列計算です。今回は例で3×3行列を扱います。
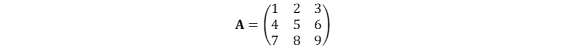
a =np.array([[1,2,3],
[4,5,6],
[7,8,9]])四則演算
和
a+a
>>>array([[2,4,6],
[8,10,12],
[14,16,18]])
差
a-a
>>>array([[0,0,0],
[0,0,0],
[0,0,0]])
商
a/a
>>>array([[1.,1.,1.],
[1.,1.,1.],
[1.,1.,1.]])
要素積
a*a
>>>array([[1,4,9],
[16,25,36],
[49,64,81]])
行列積
np.dot(a, a)
>>>array([[30,36,42],
[66,81,96],
[102,126,150]])
転置行列
転置行列は、.Tを付けるだけで可能です。
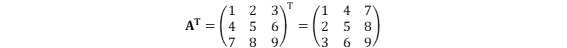
a.T
>>>array([[1,4,7],
[2,5,8],
[3,6,9]])
行列の次元変更
行列の次元を1次元にするには、.reshape(-1)とします。
b = a.reshape(-1)
b
>>>array([1, 2, 3, 4, 5, 6, 7, 8, 9])そして、3×3行列に戻したいときは、reshape(3, 3)とします。
※n×m=要素数とならなければいけないです。
b.reshape(3, 3)
>>>array([[1,2,3],
[4,5,6],
[7,8,9]])
それでは🌏
最終更新日
2020/12/31
【卒論・修論】引用・参考文献の管理法ーWordの利用ー

皆さんこんにちは!
今日は卒論・修論で多くの人が使うであろうWordの機能を使った、文献管理方法をまとめてみました。
対象
「レポートや論文でwordを使った引用・参考文献の管理をする人」
※参考文献欄をきれいに書きたい人⇒ 「文献管理と追加」へ
引用・参考文献
卒論や修論では引用や参考にする論文が少なからずあると思います。引用する際に名前だけを残しておいて、最後の文献欄に載せるのを忘れてしまったら大変です。
そういったことを避けるためにも日ごろ論文を読んだら、その都度論文の情報(少なくともタイトルやURLなど)は残しておきましょう!
書き方
文献(Reference)の書き方はジャーナルによってさまざまなので、基本的なところだけを記します。
名前
LastName, F. M., Lastname, F. M., and LastNAME, F.
おそらく使用する参考文献は英語のジャーナルが多いと思うので、上のようになっています。Lastname(姓), F(Firstnameの頭文字、名前), M(ミドルネーム(あれば))
日本語ですと単純で以下のようになります。
田中一郎, 佐藤次郎.
⇓
Tanaka, I., and Sato, J.
引用・参考文献に必要な情報(必須*)
- *著者
- *タイトル
- *年
- *ジャーナルや発行元
- ページ
- 巻(Volume)
- 号(Issue)
- DOI(Digital Object Identifier)
- URL
- アクセス年月(ホームページなどを使用した際)
etc...
Wordで管理
文献の挿入
本文途中で作成&挿入
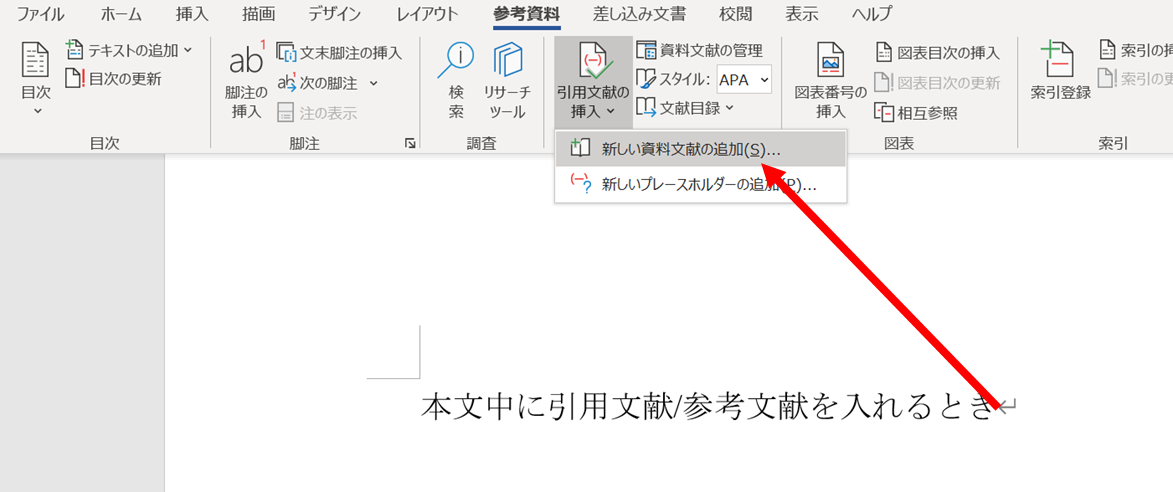
本文中で引用・参考文献を入れたいときは、
「参考資料」⇒「引用文献の挿入」⇒「新しい・・・」
とします(下図)
文献情報入力
次に文献の情報を入力します。
まずは資料文献の種類と必須項目から埋めていきます。
名前は「編集」を押すと姓・名・ミドルネームを入力できますが、白枠内にコピペorベタ打ちが速いです。
そして、必要に応じて「すべての・・フィールド表示」を選択し、論文の情報を詳細に記載します。
※必ず言語は選択しましょう!正しく表示されない場合があります。

「OK」を押して確認してみましょう。正しくカッコ書きでできていると思います。
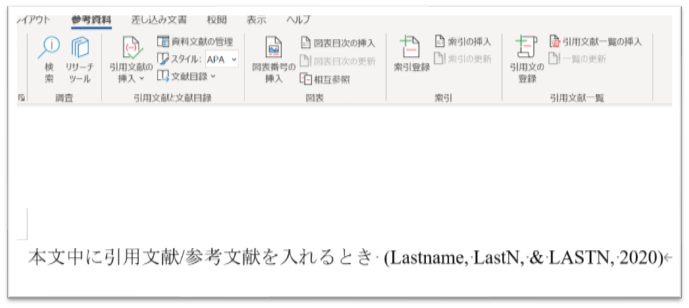
参考資料のページ作成
そして参考資料ページを新しいページに作成しておきましょう。
以下の写真のようにクリックすると、先ほど編集した論文の情報が「APA」スタイルで表示されます。
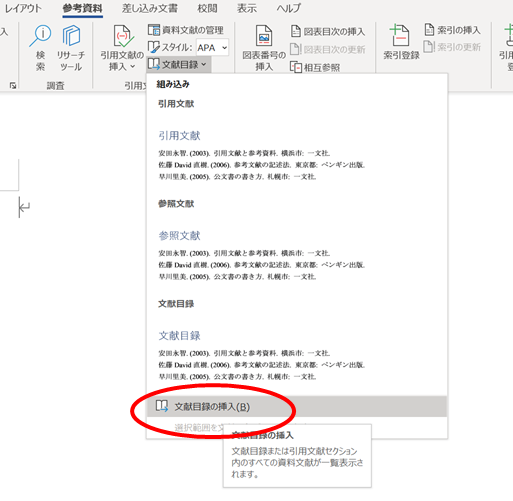
文献のスタイル変更
参考文献の表示スタイルは、Word内で10ほど用意されています。

文献の管理と追加
読んだ論文の情報をメモしましょう。
今回はNatureの最新の論文を例として使用させていただきます(REF1)。
論文を見ると必ずどこかにCITE this article的なのがあります。これを押すと引用時に必要な情報が出てくるので多用しましょう。
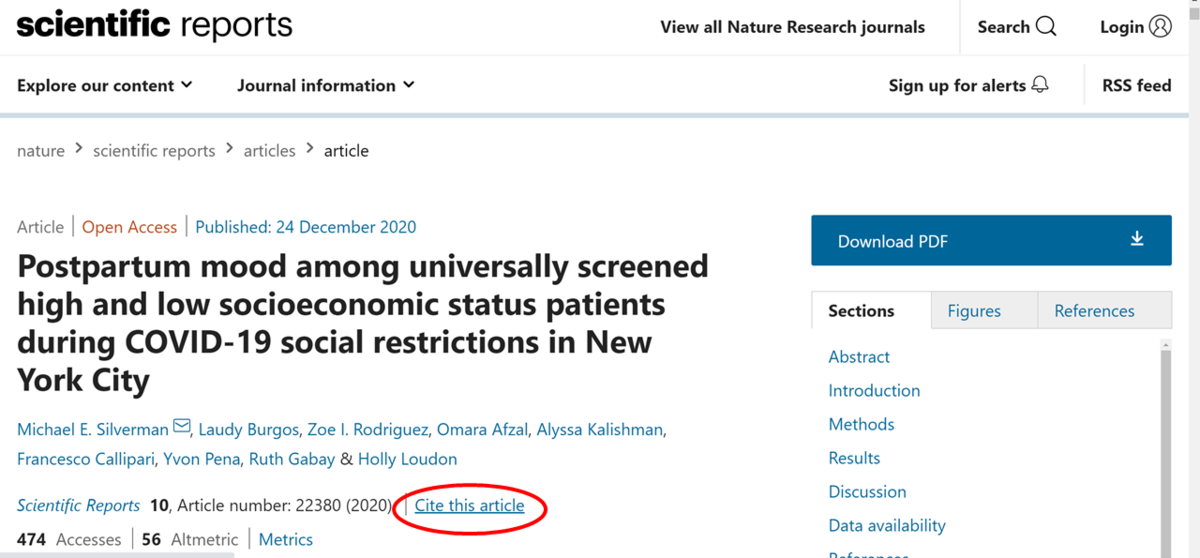
文献管理
次に、文献管理をします。
文献を追加したいときは
「資料文献の管理」⇒「作成」
で新しい文献が追加できます。
そして先ほどと同じように論文の情報を入れていき、「ok」で完了です。
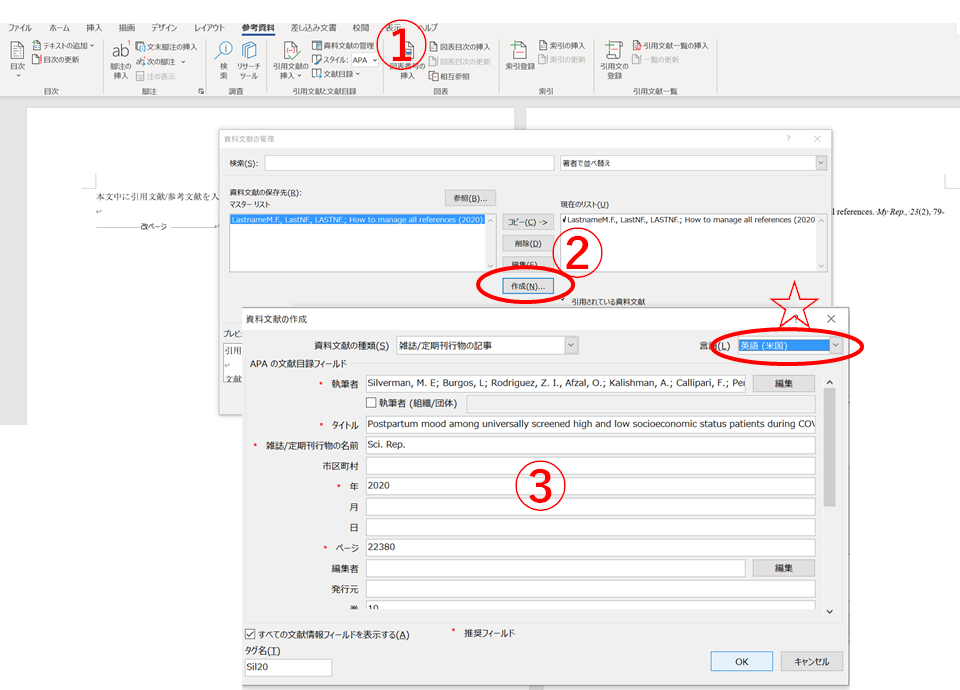
フィールドの更新
先ほどのままだと、参考文献のページが更新されていないので、フィールドの更新を行います。
フィールドの更新は参考文献の適当な箇所を右クリックすると出てきます。
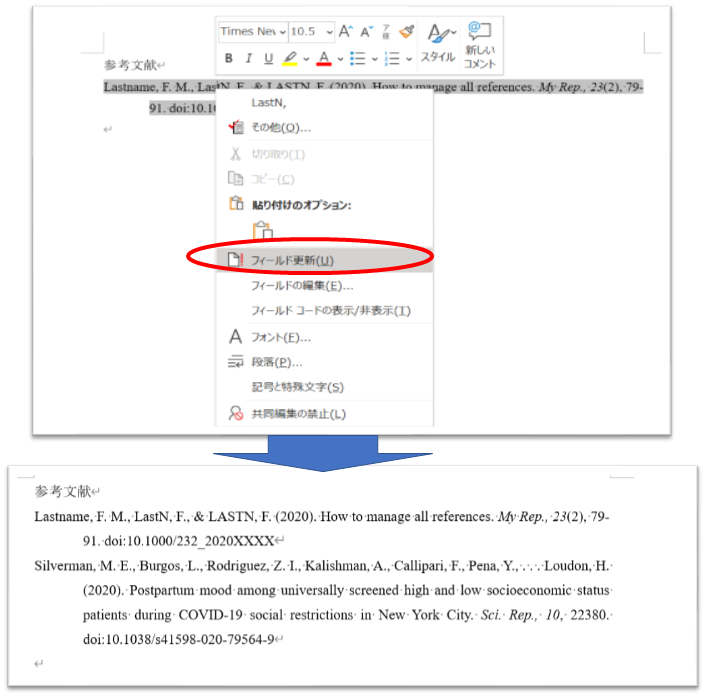
その他
注意すること
- Artical Numberがある場合はページ番号に入力
- ネットで検索した場合はURLとアクセス年月日を掲載する
et alはどうするの?
参考文献で著者が多く、et al表示したいときは「チェックボックス執筆者」をチェックし、著者の最後に「et al」と入力します。
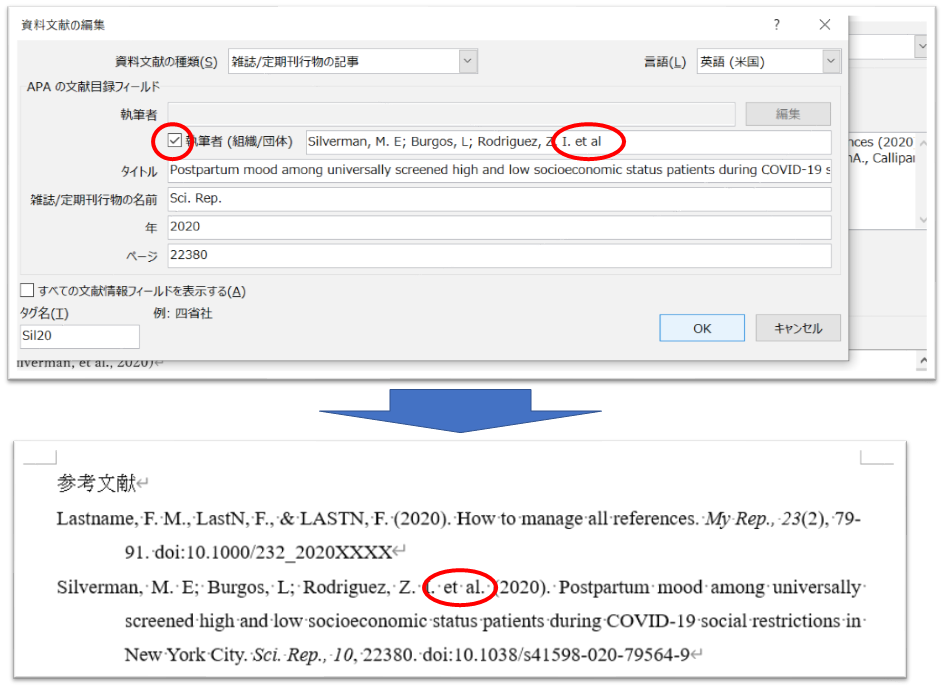
References
*1
それでは🌏
最終更新日
2020/12/30
ITパスポートの効率的な勉強法 テキストはいる?過去問はどれくらいやる?

こんにちは。
先日、
令和2年度ITパスポート試験に独学合格しました!
今回は備忘録として勉強方法を残しておきます
勉強期間は3か月です
大学の勉強があったので、1日1ー1.5時間で勉強していない日もあります...
先にタイトルの答えは
IT初心者はテキストがあったほうがいい
過去問は5年、少なくとも3年やろう
です!
使用教材・サイト
・令和02年 イメージ&クレバー方式でよくわかる 栢木先生のITパスポート教室
・ITパスポート試験ドットコム
勉強期間・量
2ヶ月あったら合格可能だと思います。
試験を受けたい日が早くに埋まってしまって、受けられないことがあるので注意してください。
1日の勉強量は平日1ー2時間、休日3時間程度取れればいいと思います。
勉強方法
具体的にテキストと過去問サイトを使った勉強方法です。
流れ
テキスト1週目(2ー3週間)
↓
テキスト2週目(1ー2週間)
↓
過去問&テキスト(1ヶ月)
(過去問道場は3段までやりました)
テキスト1週目
<進め方>
テキストを読んで(テキストの)問題を解く
☑Point
テキスト内容はすべて覚えようとしない
間違えた問題をメモしておく(付箋などで残す)
ポイントとなるところにアンダーライン
テキスト2週目
<進め方>
1週目よりしっかり読む
☑Point
用語が何を意味するのか理解する
問題は間違えたところのみ
過去問を解く
<進め方>
最新の過去問は残しておく
私はH27→R2で解きました。
各年春季と秋季があるので5年ほどやれば十分だと思います。
☑Point
100問通しで解く
間違えたところ&不安なところをチェック→テキストで復習
テストの流れ
テスト会場には試験開始20分前までに集合と確認表に書いてあります。(試験開始ギリギリに来ている人もいました。)
1)まず会場で本人確認書類+確認表を見せます。試験の注意事項の紙がもらえます。
2)ハンカチ、ティシュ、目薬以外はすべてカバンにしまいます。(ポケットの中×)
3)試験の席で確認表に書いてあるIDなどをPCに入力し試験開始を待ちます。
4)試験中~
5)早めに試験が終わったら、終了ボタンを押せば採点をしてくれて終了です!
試験終了後1時間以内に試験結果のレポートが来ました。
試験を受けてみて
過去問を解いて薄々気づいていたのですが、個人的には令和に入ってからの問題が難しいと感じました。
平成の問題は8-9割は安定してとれたのですが、令和の問題で意外とわからない単語があった気がします。
勉強方法は人それぞれですが、
インプット(参考書)⇄アウトプット(過去問)は大切です。
学生はこの試験を受けるメリットがあると思います。
例えば、
・ITに関する基本的な事柄を学べる。
・テクノロジ面だけではなくマネジメント・ストラテジ面を学べる。
・試験頻度が高く勉強を効率的にアウトプットできる。
などです。
次は基本情報技術者試験に向けてコツコツ頑張ります!
それでは🌏
【Matplotlib 】PythonでMatplotlibカラーバーの色を利用したプロット
皆さんこんにちは。
今日はMatplotlibカラーバーを利用したプロットに関してです。
以前、グラデーションカラーを生成してテキストファイルに出力する方法をご紹介しましたが、おそらくこちらの記事のほうが便利です。
解説
モジュール
まずはモジュールをインポートします。
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.cm as cm使用データ
次に、データを用意します。
この記事では、月ごとにグラフを変えて(12本のグラフの作成)、x軸は年、y軸のデータは適当な2次元のデータです
x = np.arange(2015, 2020, 1)
y = np.arange(0, 5*12).reshape(12, 5)
month = np.arange(1, 13, 1)プロット
次にプロットしていきます。
例えばcolormapのjetを使用するとき、グラフを12個分作成するので、
color=cm.jet(0-1の数字)とします。
したがって、
fig = plt.figure(figsize=(10, 5))
plt.rcParams["font.size"] = 12
for i in range(12):
plt.plot(x, y[i], label=month[i], color=cm.jet(i/12))
plt.legend()

+α
ちなみにカラーバーを逆転したい場合は
指定したいカラーの後ろに「_r」をつけてみてください
多分Reverseのrです。
ほかのカラーでも試してみてください!
それでは🌏
参考文献
matplotlibで色をグラデーション的に選択 - Qiita
【卒論・修論】フォントの種類を一括設定(パワーポイント; PowerPoint, ワード;Word)

こんにちは。
今日はレポートや発表に必須なパワポとワードの一括設定に関する内容です。
レポートのフォント
フォントサイズ:10.5
フォント:日本語 MS 明朝、 英数字 Times New Roman
Word
まずはワードのフォント一括設定です。
- 「ホーム」の「フォント」の右下をクリック
- デフォルト(既定)のフォントやサイズなどを選択
- 「既定に設定」をクリック
- 「この文書だけ」か「Normalテンプレート...」のどちらかを選択して完了
「Normalテンプレート...」を選択すると、今後WordをNormalで作成する時にそのフォントのスタイルとなる!

PowerPoint
次にパワポの一括設定です。
- 「表示」の「スライドマスター」を選択
- 「フォント」を選択
- 「フォントのカスタマイズ」で自分好みにフォントを選択⇒保存
- 最後に「マスター表示を閉じる」で完了

レポート・卒論・修論頑張りましょう!!
それでは🌏
Python 違う階層のファイルを読み込む(READ)

【Matplotlib 】Python Matplotlibでトラジェクトリー描写
こんにちは。今日はトラジェクトリーのデータを高度分布とともにプロットする方法です。
データは各自でご用意ください。
必要な知識
Matplotlibの基礎
Python-時系列プロット(気温ー日平均) - RuntaScience diary
Python 軸を日付フォーマットに変更 - RuntaScience diary
グラフ分割の基礎
Python matplotlibのGridspecーグラフの柔軟な分割(3:1でもで4:1でも) - RuntaScience diary
PBLH
Planetary Boundary Layer Height;大気境界層高度
大気境界層(地表面の影響を受ける層で、地上から1ー3 kmの層)と自由大気層(その影響がない)の境界
データ
始める前にデータをインポートしてください。
データフレーム(df)でもarrayでも大丈夫です。
必要なのは、緯度経度のデータ・時間のデータ・高度のデータです。
今回私は適当に作成したエクセルファイルをdfに入れて使います。
| Time | latitude | longitude | hight | pblh | |
|---|---|---|---|---|---|
| 0 | 2020-06-01 00:00:00 | 35.68944 | 139.69167 | 20 | 1000 |
| 1 | 2020-06-01 01:00:00 | 35.58944 | 139.59167 | 30 | 950 |
| 2 | 2020-06-01 02:00:00 | 35.68944 | 139.49167 | 20 | 1000 |
| 3 | 2020-06-01 03:00:00 | 35.78944 | 139.39167 | 10 | 950 |
| 4 | 2020-06-01 04:00:00 | 35.88944 | 139.29167 | 20 | 1000 |
| ... | ... | ... | ... | ... | ... |
| 259 | 2020-06-11 19:00:00 | 44.98944 | 121.99167 | 90 | 450 |
| 260 | 2020-06-11 20:00:00 | 44.88944 | 122.09167 | 80 | 400 |
| 261 | 2020-06-11 21:00:00 | 44.98944 | 121.99167 | 70 | 450 |
| 262 | 2020-06-11 22:00:00 | 45.08944 | 121.89167 | 60 | 400 |
| 263 | 2020-06-11 23:00:00 | 45.18944 | 121.79167 | 70 | 450 |
モジュール
まずは必要なモジュールをインポートします。
import matplotlib.pyplot as plt #描写
from matplotlib import gridspec #グラフ分割のため
#cartopy
import cartopy.crs as ccrs
import matplotlib.ticker as mticker #緯度経度グリッド作成のため
from cartopy.mpl.gridliner import LONGITUDE_FORMATTER, LATITUDE_FORMATTER #緯度経度線を度数表示にするため
import cartopy.feature as cfeature #国境線引くため
import numpy as np #数値計算
import pandas as pd #データ読み込み用
#時間軸作成のため
from matplotlib import dates as mdates
from matplotlib.dates import DateFormatter
import datetime
描写
#グラフ fig = plt.figure(figsize=(12,18)) gs = gridspec.GridSpec(2, 1, height_ratios=(3, 1)) #*1 plt.rcParams["font.size"] = 18 #*2 plt.suptitle("Trajectory", y=0.9) #3 #上図 ax1=fig.add_subplot(gs[0:1, :], projection=ccrs.PlateCarree()) #1 ax1.coastlines(resolution="50m") #緯度・経度線のグリッドの設定 #4 gl = ax1.gridlines(crs=ccrs.PlateCarree(), draw_labels=True, linewidth=2, color="gray", alpha=0.5, linestyle=":") gl.xlabels_top = False gl.ylabels_right = False dlon, dlat = 10,10 xticks = np.arange(-180, 180.1, dlon) yticks = np.arange(-90, 90.1, dlat) gl.xlocator = mticker.FixedLocator(xticks) gl.ylocator = mticker.FixedLocator(yticks) gl.xformatter = LONGITUDE_FORMATTER gl.yformatter = LATITUDE_FORMATTER gl.xlabel_style = {"size": 20} gl.ylabel_style = {"size": 20} ax1.add_feature(cfeature.BORDERS, linestyle="--", linewidth=1) #国境線 lon = df["longitude"] lat = df["latitude"] ax1.plot(lon,lat) #上グラフの範囲([経度min, 経度max, 緯度min, 緯度max]) ax1.set_extent([119.9, 148, 25, 50.1], crs=ccrs.PlateCarree()) #目盛りの表示形式を度数表記に ax1.xaxis.set_major_formatter(LongitudeFormatter(zero_direction_label=True)) ax1.yaxis.set_major_formatter(LatitudeFormatter()) #=============================================================================== # 下のグラフ ax2=fig.add_subplot(gs[-1, :]) #1 t = df["Time"] h=df["hight"] ax2.plot(t,h,label="trajectory") pblh=df["pblh"] ax2.plot(t,pblh,"--",label="PBLH",color="gray") #軸の設定 #*5 ax2.set_xlim(t.min(), t.max()) ax2.tick_params(axis="both", which="major",direction="in",length=7,width=2,top="on",right="on") ax2.xaxis.set_major_formatter(DateFormatter("%b-%d")) ax2.xaxis.set_major_locator(mdates.DayLocator(interval=1)) #ラベル ax2.set_xlabel("Time") ax2.set_ylabel("Hight(m)") ax2.legend() #グラフ間の隙間 #6 plt.subplots_adjust(hspace=0.04) plt.show() fig.savefig("XXX.png", format="png",dpi=330)

Keys
1) グラフ分割:縦を3:1の2つに分割、横は1
2) 一括でフォントサイズ設定
3) 全体のタイトル。yで縦方向の位置を設定
4)詳しくは
Cartopy-Pythonを用いた、Merra-2の利用 - RuntaScience diary
5)詳しくは
Python-時系列プロット(気温ー日平均) - RuntaScience diary
6)hspaceで上下のスペース、wspaceで左右のスペース
それでは 🌏
【Matplotlib】エラーバーをfill_betweenで表示
こんにちは。
今日はエラーバーをfill_betweenを用いて表示してみたいと思います。
エラーバーと回帰直線の相関プロットについてです↓
使い方
x軸はxで、y1からy2の間を塗りつぶす
ax.fill_between(x, y1, y2)
例)y=0とy=x²の間を塗りつぶす
import numpy as np
import matplotlib.pyplot as plt
x = np.arange(-10, 10, 1)
y0 = x * 0
y = x ** 2
plt.fill_between(x, y0, y)

モジュール
まず必要なモジュールをインポートします。
import numpy as np
import matplotlib.pyplot as plt
描写
例1
まずは、1つのデータから描写します。
データは今回は適当なものを使います。
x = np.arange(1,23,2)
y = np.array([2,3,6,5,10,10,12,14,18,20,20])
#標準偏差を想定
y_err = np.array([0.6, 0.7, 0.5, 0.8, 0.5, 0.3, 0.2, 0.3, 0.6, 0.9, 0.7]) * 3
def main():
fig = plt.figure(figsize=(10,5))
plt.rcParams["font.size"] = 18
ax = plt.subplot(111)
ax.plot(x, y, marker="o")
ax.fill_between(x, y+y_err, y-y_err, alpha=0.15)
#範囲の設定
ax.set_xlim(0, 24)
ax.set_ylim(0, 25)
#メモリの設定
ax.minorticks_on() #補助メモリの描写
ax.tick_params(axis="both", which="major",direction="in",length=5,width=2,top="on",right="on")
ax.tick_params(axis="both", which="minor",direction="in",length=2,width=1,top="on",right="on")
#ラベルの設定
ax.set_title("Errorbar")
ax.set_xlabel("X-axis")
ax.set_ylabel("Y-axis")
ax.grid()
plt.show()
#保存
# fig.savefig("XXX.png",format="png", dpi=300)
if __name__ == "__main__":
main()

例2
例1のfill_betweenはalphaを設定すると、重なった部分がきれいに表示されます。
x = np.arange(1,23,2)
y1 = np.array([2,3,6,5,10,10,12,14,18,20,20])
y1_err = np.array([0.6, 0.7, 0.5, 0.8, 0.5, 0.3, 0.2, 0.3, 0.6, 0.9, 0.7]) * 1.2
y2 = y1 + np.random.rand() * 4
y2_err = y1_err + np.random.rand()
def main():
fig = plt.figure(figsize=(10,5))
plt.rcParams["font.size"] = 18
ax = plt.subplot(111)
ax.plot(x, y1, marker="o")
ax.fill_between(x, y1+y1_err, y1-y1_err, alpha=0.15)
ax.plot(x, y2, marker="o")
ax.fill_between(x, y2+y2_err, y2-y2_err, alpha=0.15)
#範囲の設定
ax.set_xlim(0, 24)
ax.set_ylim(0, 25)
#メモリの設定
ax.minorticks_on() #補助メモリの描写
ax.tick_params(axis="both", which="major",direction="in",length=5,width=2,top="on",right="on")
ax.tick_params(axis="both", which="minor",direction="in",length=2,width=1,top="on",right="on")
#ラベルの設定
ax.set_title("Errorbar")
ax.set_xlabel("X-axis")
ax.set_ylabel("Y-axis")
ax.grid()
plt.show()
#保存
# fig.savefig("XXX.png",format="png", dpi=300)
if __name__ == "__main__":
main()

【データ解析】Pythonでデータ解析[基礎]ー繰り返し(for)・条件分岐(if elif else)

こんにちは
今日はpythonでデータ解析の基礎です
ループ(for)
基礎
for i in range(2):
print(i)
>>>0
1
for i in range(1, 5, 1):
print(i)
>>>1
2
3
4
ループ×配列
x_list = []
for i in range(10):
data = i * i
x_list.append(data)
x_list
>>>[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
np.array(x_list)
>>>array([ 0, 1, 4, 9, 16, 25, 36, 49, 64, 81])
条件分岐
a = 100
if a > 100:
print("a>100")
elif a == 100:
print("a=100")
else:
print("a<100")
>>>a=100
ループ×条件分岐
continueとbreak
continue: 通過するとforに進む
break: 通過するとforを抜け出す
for i in range(15):
if i % 2 == 0:
continue
elif i == 15:
break
print(i)
>>>1
3
5
7
9
11
13
if・elif・else
3の倍数かつ5の倍数⇒FizzBuzz
3の倍数⇒Fizz
5の倍数⇒Buzz
for i in range(15):
a = i + 1
if (a % 3 == 0)&(a % 5 == 0):
print("{}:FizzBuzz".format(a))
elif a % 3 == 0:
print("{}:Fizz".format(a))
elif a % 5 == 0:
print("{}:Buzz".format(a))
else:
print("{}:×".format(a))
>>>1:×
2:×
3:Fizz
4:×
5:Buzz
6:Fizz
7:×
8:×
9:Fizz
10:Buzz
11:×
12:Fizz
13:×
14:×
15:FizzBuzz
format文はこちらから
それでは🌏
【データ解析】Pythonでデータ解析[基礎]ー数と文字・計算・配列・行列

こんにちは
今日はpythonでデータ解析の基礎です
数と文字
主に用いられる型(type)

整数(int)
a = 4
type(a)
>>>int浮動小数点(float)
b = 4.4
type(b)
>>>float
b2 = 1/3
type(b2)
>>>float真偽(True or False)
c = True
type(c)
>>>True
文字列(str)
d = "NAME"
type(d)
>>>str
日付(datetime)
import pandas as pd
e = pd.to_datetime("2019-01-01 12:30")
print(e)
type(e)
>>>2019-01-01 12:30:00
pandas._libs.tslibs.timestamps.Timestamp
リスト(list)
f = [1, 2, 3, 4]
type(f)
>>>list
辞書
g = {"A1":1, "A2":2, "A3":3, "A5":4}
type(g)
>>>dict
タプル
h = (1, 2, 3, 4)
type(h)
>>>tuple
セット
i = {1, 2, 3, 4}
type(i)
>>>set
配列(array)
import numpy as np
j = np.arange(1,5,1)
type(j)
>>>numpy.ndarray
関数
def my_name(name):
print(name)
my_name("Alex")
type(my_name)
>>>Alex
function
計算
基本的な計算から、行列計算までです
加法・減法・乗法・除法
1 + 4
>>>5
4 - 1
>>>3
11 * 12
>>>132
33 / 3
>>>11.0
11 % 2
>>>1
配列
np.arange(x, y, n)
xからyまでのn間隔の配列の作成
注意するのは、y-1しか数が並ばないこと。
a = np.arange(1, 10, 1)
a
>>>array([1, 2, 3, 4, 5, 6, 7, 8, 9])
a2 = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9])
a2
>>>array([1, 2, 3, 4, 5, 6, 7, 8, 9])
.reshape(行, 列)で配列の次元を変更できます。
#2次元配列作成
b = np.arange(1, 51, 1).reshape(5, 10)
b
>>>array([[ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
[11, 12, 13, 14, 15, 16, 17, 18, 19, 20],
[21, 22, 23, 24, 25, 26, 27, 28, 29, 30],
[31, 32, 33, 34, 35, 36, 37, 38, 39, 40],
[41, 42, 43, 44, 45, 46, 47, 48, 49, 50]])
.reshape(-1,)で1次元配列に戻せます
b2 = b.reshape(-1,)
b2
>>>array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,
18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34,
35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50])
最後に配列の情報を確認しておきましょう。
print(b.shape) #配列の形
print(b.ndim) #配列の次元
print(b.size) #配列のサイズ
>>>(5, 10)
>>>2
>>>50
行列計算
基礎

A = np.array([[2, 2], [2, 4]])
A
>>>array([[2, 2],
[2, 4]])
A + 10
>>>array([[12, 12],
[12, 14]])
A + A
>>>array([[4, 4],
[4, 8]])
A * 3
>>>array([[ 6, 6],
[ 6, 12]])
※行列の掛け算ではなく、要素の掛け算である
A * A
>>>array([[ 4, 4],
[ 4, 16]])
行列の積(3種類の計算方法)
A @ A
np.dot(A, A)
A.dot(A)
>>>array([[ 8, 12],
[12, 20]])
転置行列・逆行列・単位行列

np.transpose(A)
>>>array([[2, 2],
[2, 4]])

inv_A = np.linalg.inv(A)
inv_A
>>>array([[ 1. , -0.5],
[-0.5, 0.5]]) A.dot(inv_A)
# np.dot(A, inv_A)
>>>array([[1., 0.],
[0., 1.]])
B = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
B
>>>array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
#逆行列
inv_B = np.linalg.inv(B)
inv_B
>>>array([[ 3.15251974e+15, -6.30503948e+15, 3.15251974e+15],
[-6.30503948e+15, 1.26100790e+16, -6.30503948e+15],
[ 3.15251974e+15, -6.30503948e+15, 3.15251974e+15]])#元の行列×逆行列
B.dot(inv_B)
>>>array([[ 0. , 1. , -0.5],
[ 0. , 2. , -1. ],
[ 0. , 3. , 2.5]])⇑単位行列が求まっていない
それは、元の行列の行列式≠0を満たしていないからである
int(np.linalg.det(B))
>>>0行列式

np.linalg.det(A)
>>>4.0
固有値と固有ベクトル

A = np.array([[2, 2], [2, 4]])
A
>>>array([[2, 2],
[2, 4]])
w, v = np.linalg.eig(A)
print(w) #固有値
print(v) #固有ベクトル
>>>[0.76393202 5.23606798]
[[-0.85065081 -0.52573111]
[ 0.52573111 -0.85065081]]
それでは🌏
【Pandas】 データをファイルに格納(保存; WRITE)

こんにちは。今日は作成したデータを保存する方法です。
データフレーム
まずはモジュールをインポートします。
import pandas as pd
使用するデータは、以下のデータフレームです。
print(df)>>>
| Year | Month | Day | Data | |
|---|---|---|---|---|
| 0 | 2019 | 1 | 1 | 12 |
| 1 | 2019 | 2 | 1 | 14 |
| 2 | 2019 | 3 | 1 | 13 |
| 3 | 2019 | 4 | 1 | 12 |
| 4 | 2019 | 5 | 1 | 13 |
| 5 | 2019 | 6 | 1 | 11 |
| 6 | 2019 | 7 | 1 | 14 |
| 7 | 2019 | 8 | 1 | 12 |
| 8 | 2019 | 9 | 1 | 14 |
| 9 | 2019 | 10 | 1 | 14 |
| 10 | 2019 | 11 | 1 | 11 |
| 11 | 2019 | 12 | 1 | 15 |
テキストファイル
indexまで保存されるので、読みこみの時は、indexを指定しましょう
保存時にindexを除きたい場合は、
df.to_csv("XXX.txt", index=False)
としましょう。
カンマ区切り
#データの保存
df.to_csv("XXX.txt")
#確認
pd.read_csv("XXX.txt", index_col=0)
タブ区切り
#データの保存
df.to_csv("XXX.txt",sep="\t")
#確認
pd.read_table("XXX.txt",index_col=0)
エクセルファイル
#データの保存
df.to_excel("XXX.xlsx",sheet_name="X")
#確認
pd.read_excel("XXX.xlsx",index_col=0,sheet_name="X")
複数データを同時に
複数のデータフレームを1つのファイルにシートを分けて保存するには、ExcelWriterを使います。
例として、データフレームをdf1, df2, df3とします
path = "XXX.xlsx"
with pd.ExcelWriter(path) as writer:
df1.to_excel(writer, sheet_name = "sheet1")
df2.to_excel(writer, sheet_name = "sheet2")
df3.to_excel(writer, sheet_name = "sheet3")
バイナリデータ(配列;Array)
まずはモジュールをインポートします。
import numpy as np今回は1次元の配列データと2次元の配列データを保存します。
lon = np.arange(-180,180,0.1)
lat = np.arange(-90, 90, 0.1)
two_dim = np.arange(0,150,1).reshape(10,15)
print(lon, lat, two_dim)
>>>[-180. -179.9 -179.8 ... 179.7 179.8 179.9]
>>>[-90. -89.9 -89.8 ... 89.7 89.8 89.9]
>>>[[ 0 1 ... 12 13 14][ 15 16 ... 27 28 29]...
...[120 121 ... 132 133 134] [135 136 ... 147 148 149]]
保存します。
np.save("XXX1.npy", lon)
np.save("XXX2.npy", lat)
np.save("XXX3.npy", two_dim)読み込んでデータがしっかり入っていることを確認しましょう
np.load("XXX1.npy")
>>>[-180. -179.9 -179.8 ... 179.7 179.8 179.9]
読み込みに関しては前の記事で紹介しています。
それでは🌏
【Pandas】ファイルをデータフレームに格納(読み込み; READ)

こんにちは。今日はファイルの読み込みについてです。
テキストファイル
まずはモジュールをインポートします。
import numpy as np
カンマ区切り
pd.read_csv("XXX.txt")
カンマで区切ってあるテキストファイルをインポートします。
データ⇓
Year, Month, Day, Data 2019, 1, 1, 12 2019, 2, 1, 14 2019, 3, 1, 13 2019, 4, 1, 12 2019, 5, 1, 10 2019, 6, 1, 10 2019, 7, 1, 15 2019, 8, 1, 12 2019, 9, 1, 10 2019, 10, 1, 12 2019, 11, 1, 10 2019, 12, 1, 12
df = pd.read_csv("XXX.txt")
df
| Year | Month | Day | Data | |
|---|---|---|---|---|
| 0 | 2019 | 1 | 1 | 12 |
| 1 | 2019 | 2 | 1 | 14 |
| 2 | 2019 | 3 | 1 | 13 |
| 3 | 2019 | 4 | 1 | 12 |
| 4 | 2019 | 5 | 1 | 10 |
| 5 | 2019 | 6 | 1 | 10 |
| 6 | 2019 | 7 | 1 | 15 |
| 7 | 2019 | 8 | 1 | 12 |
| 8 | 2019 | 9 | 1 | 10 |
| 9 | 2019 | 10 | 1 | 12 |
| 10 | 2019 | 11 | 1 | 10 |
| 11 | 2019 | 12 | 1 | 12 |
タブ区切り
pd.read_table("XXX.txt")
タブ区切りのテキストファイルも同様にデータフレームに格納できます
Year Month Day Data 2019 1 1 12 2019 2 1 14 2019 3 1 13 2019 4 1 12 2019 5 1 13 2019 6 1 11 2019 7 1 14 2019 8 1 12 2019 9 1 14 2019 10 1 14 2019 11 1 11 2019 12 1 15
1)
df = pd.read_table("XXX.txt")
df
2)
df = pd.read_csv("XXX.txt",sep="\t")
df
| Year | Month | Day | Data | |
|---|---|---|---|---|
| 0 | 2019 | 1 | 1 | 12 |
| 1 | 2019 | 2 | 1 | 14 |
| 2 | 2019 | 3 | 1 | 13 |
| 3 | 2019 | 4 | 1 | 12 |
| 4 | 2019 | 5 | 1 | 10 |
| 5 | 2019 | 6 | 1 | 10 |
| 6 | 2019 | 7 | 1 | 15 |
| 7 | 2019 | 8 | 1 | 12 |
| 8 | 2019 | 9 | 1 | 10 |
| 9 | 2019 | 10 | 1 | 12 |
| 10 | 2019 | 11 | 1 | 10 |
| 11 | 2019 | 12 | 1 | 12 |
エクセルファイル
エクセルファイルも同様のデータを使います。
基本
| Year | Month | Day | Data |
| 2019 | 1 | 1 | 12 |
| 2019 | 2 | 1 | 14 |
| 2019 | 3 | 1 | 13 |
| 2019 | 4 | 1 | 12 |
| 2019 | 5 | 1 | 13 |
| 2019 | 6 | 1 | 11 |
| 2019 | 7 | 1 | 14 |
| 2019 | 8 | 1 | 12 |
| 2019 | 9 | 1 | 14 |
| 2019 | 10 | 1 | 14 |
| 2019 | 11 | 1 | 11 |
| 2019 | 12 | 1 | 15 |
df = pd.read_excel("XXX.xlsx")
dfシート名・インデックスを指定したい場合
sheet ="b"でインデックスをidxで指定する場合は、

df = pd.read_excel("XXX.xlsx", sheet_name="b",index_col=0)
df
| Year | Month | Day | Data | |
|---|---|---|---|---|
| idx | ||||
| 1 | 2019 | 1 | 1 | 12 |
| 2 | 2019 | 2 | 1 | 14 |
| 3 | 2019 | 3 | 1 | 13 |
| 4 | 2019 | 4 | 1 | 12 |
| 5 | 2019 | 5 | 1 | 13 |
| 6 | 2019 | 6 | 1 | 11 |
| 7 | 2019 | 7 | 1 | 14 |
| 8 | 2019 | 8 | 1 | 12 |
| 9 | 2019 | 9 | 1 | 14 |
| 10 | 2019 | 10 | 1 | 14 |
| 11 | 2019 | 11 | 1 | 11 |
| 12 | 2019 | 12 | 1 | 15 |
データの一部のみ使いたい
| Year | Month | Day | Data_x1 | Data_x2 | Data_y1 | Data_y2 |
| 2019 | 1 | 1 | 12 | 12 | 12 | 12 |
| 2019 | 2 | 1 | 14 | 14 | 14 | 14 |
| 2019 | 3 | 1 | 13 | 13 | 13 | 13 |
| 2019 | 4 | 1 | 12 | 12 | 12 | 12 |
| 2019 | 5 | 1 | 13 | 13 | 13 | 13 |
| 2019 | 6 | 1 | 11 | 11 | 11 | 11 |
| 2019 | 7 | 1 | 14 | 14 | 14 | 14 |
| 2019 | 8 | 1 | 12 | 12 | 12 | 12 |
| 2019 | 9 | 1 | 14 | 14 | 14 | 14 |
| 2019 | 10 | 1 | 14 | 14 | 14 | 14 |
| 2019 | 11 | 1 | 11 | 11 | 11 | 11 |
| 2019 | 12 | 1 | 15 | 15 | 15 | 15 |
1)データを含む
include=["Data_x1"]
df = pd.read_excel("XXX.xlsx", sheet_name="c",usecols=include)
df
| Data_x1 | |
|---|---|
| 0 | 12 |
| 1 | 14 |
| 2 | 13 |
| 3 | 12 |
| 4 | 13 |
| 5 | 11 |
| 6 | 14 |
| 7 | 12 |
| 8 | 14 |
| 9 | 14 |
| 10 | 11 |
| 11 | 15 |
2)データを抜く
exclude=["Data_x2", "Data_y2"] #抜く列
df = pd.read_excel("XXX.xlsx", sheet_name = "c",usecols = lambda x: x not in exclude)
df| Year | Month | Day | Data_x1 | Data_y1 | |
|---|---|---|---|---|---|
| 0 | 2019 | 1 | 1 | 12 | 12 |
| 1 | 2019 | 2 | 1 | 14 | 14 |
| 2 | 2019 | 3 | 1 | 13 | 13 |
| 3 | 2019 | 4 | 1 | 12 | 12 |
| 4 | 2019 | 5 | 1 | 13 | 13 |
| 5 | 2019 | 6 | 1 | 11 | 11 |
| 6 | 2019 | 7 | 1 | 14 | 14 |
| 7 | 2019 | 8 | 1 | 12 | 12 |
| 8 | 2019 | 9 | 1 | 14 | 14 |
| 9 | 2019 | 10 | 1 | 14 | 14 |
| 10 | 2019 | 11 | 1 | 11 | 11 |
| 11 | 2019 | 12 | 1 | 15 | 15 |
3)header飛ばし
| data:2019/1/1 | |||
| Site:Japan | |||
| Year | Month | Day | Data |
| 2019 | 1 | 1 | 12 |
| 2019 | 2 | 1 | 14 |
| 2019 | 3 | 1 | 13 |
| 2019 | 4 | 1 | 12 |
| 2019 | 5 | 1 | 13 |
| 2019 | 6 | 1 | 11 |
| 2019 | 7 | 1 | 14 |
| 2019 | 8 | 1 | 12 |
| 2019 | 9 | 1 | 14 |
| 2019 | 10 | 1 | 14 |
| 2019 | 11 | 1 | 11 |
| 2019 | 12 | 1 | 15 |
df = pd.read_excel("XXX.xlsx", sheet_name = "a",header = 3)
df
| Year | Month | Day | Data | |
|---|---|---|---|---|
| 0 | 2019 | 1 | 1 | 12 |
| 1 | 2019 | 2 | 1 | 14 |
| 2 | 2019 | 3 | 1 | 13 |
| 3 | 2019 | 4 | 1 | 12 |
| 4 | 2019 | 5 | 1 | 13 |
| 5 | 2019 | 6 | 1 | 11 |
| 6 | 2019 | 7 | 1 | 14 |
| 7 | 2019 | 8 | 1 | 12 |
| 8 | 2019 | 9 | 1 | 14 |
| 9 | 2019 | 10 | 1 | 14 |
| 10 | 2019 | 11 | 1 | 11 |
| 11 | 2019 | 12 | 1 | 15 |
netCDFファイル
まずはモジュールをインポート
from netCDF4 import Dataset
nc = Dataset("XXX.nc4", mode="r")
nc
<データの情報が出てくる>・・・・データの情報を基に、データをarrayにする。
data = nc.variables["dataname"][:].data #1次元データの場合
data
>>>array([100,120,122,111,92,222,…, 128, 100])
それでは🌏