【Pandas】Python Pandas基礎編(DataFrame作成・選択)

こんにちは
今日はPandasの基本的な使用方法について話していきたいと思います!
Pandasとは、Pythonでのデータ解析に用いられるライブラリのこと。
DataFrame作成
まず初めに、pandasをインポートしていきましょう
import pandas as pd
インポートする
テキストファイルやExcelファイルからインポートすることによって、DataFrameを作成できます。
詳しくは以下の記事をご覧ください。
リスト・配列から作成
リストと配列からDataFrameを作成することができます。
データフレームとして読み取ったデータは慣習的にdfと定義します。
今回以下の配列とリストを用意しました。
import numpy as np
data_arr1 = np.arange(10)
data_list1 = [0,1,2,3,4,5,6,7,8,9]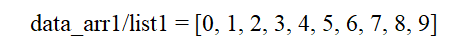
それでは
pd.DataFrame(Data, index, columns, dtype)で変換します。
Columns(カラム)
df1 = pd.DataFrame(data_arr1,columns=["data"])
# df = pd.DataFrame(data_list1,columns=["data"])
df1
※列名をcolumnsで 指定できます。
※リストと配列は同じデータフレームを返すので、リストのほうをコメントアウトしています。
Index(インデックス)
idx_list =["A","B", "C","D","E","F","G","H","I","J"]
df2 = pd.DataFrame(data_arr1,index=idx_list,columns=["data"])
df2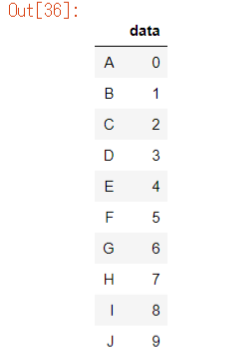
※インデックス名をindexで 指定できます。
dtype
df3 = pd.DataFrame(data_arr1,columns=["data"], dtype=float)
df3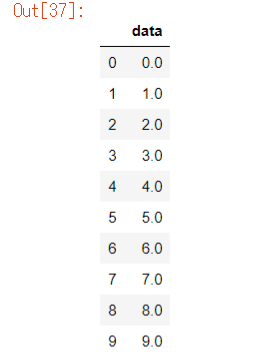
※データフレームのdtypeを 指定できます。
n×mのDF
listではn×mの行列をデータフレームに変換できませんが、配列なら可能です。
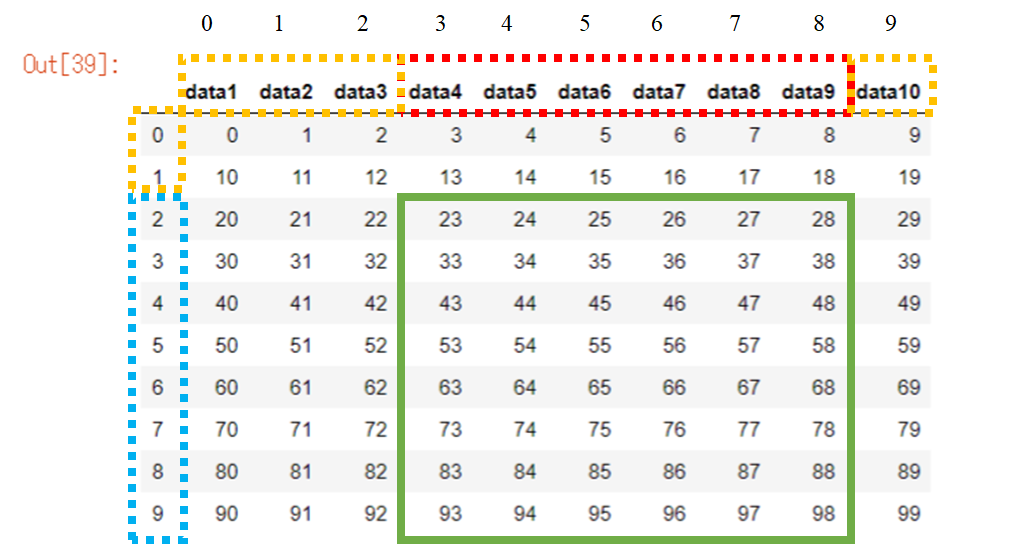
例として、10×10の配列を以下のように定義します 。
data_arr2 = np.arange(10*10).reshape(10,10)
data_arr2
>>>array([[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
[20, 21, 22, 23, 24, 25, 26, 27, 28, 29],
[30, 31, 32, 33, 34, 35, 36, 37, 38, 39],
[40, 41, 42, 43, 44, 45, 46, 47, 48, 49],
[50, 51, 52, 53, 54, 55, 56, 57, 58, 59],
[60, 61, 62, 63, 64, 65, 66, 67, 68, 69],
[70, 71, 72, 73, 74, 75, 76, 77, 78, 79],
[80, 81, 82, 83, 84, 85, 86, 87, 88, 89],
[90, 91, 92, 93, 94, 95, 96, 97, 98, 99]])
そしてこれをデータフレームに変換します。
col_list = ["data1", "data2", "data3", "data4", "data5", "data6", "data7", "data8", "data9", "data10"]
df4 = pd.DataFrame(data_arr2,columns=col_list)
df4
データの選択
データフレームはエクセルファイルのように扱うことができます。
例えば、日付とその日の気温が入ったファイルをデータフレームとして読み込み、
春の期間だけのデータを抽出したり、気温が20度以上の日のデータのみを抽出したりできます。
以下のデータ(先ほどのdf4)を使用します。
df4⇓

loc
まずはlocです。locはデータフレームの必要な情報のみをカラムを基準として抜き取れます。
条件ひとつ
まずはカラムdata3の値が60未満を満たすデータフレームを選択します
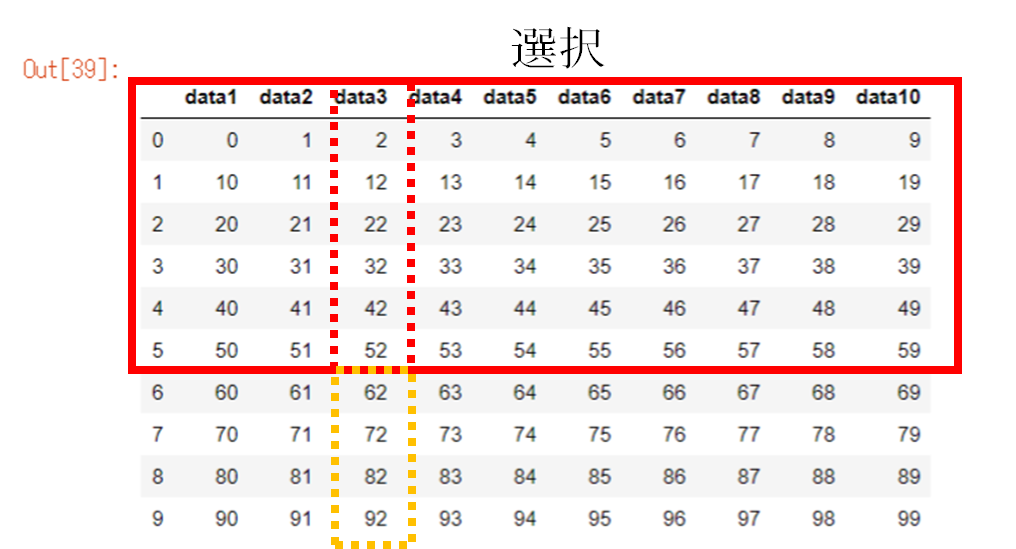
df5 = df.loc[df["data3"] < 60]
df5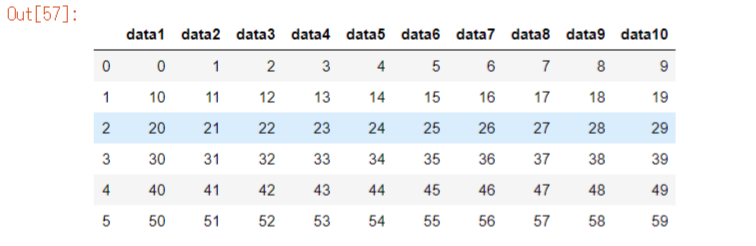
複数条件
以下のような範囲設定もできます。
30≦data3≦60

df6 = df.loc[(df["data3"] >= 30) & (df["data3"] <= 60)].reset_index(drop=True)
df6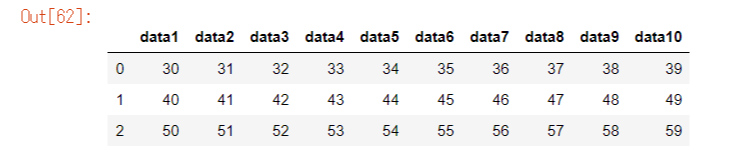
※&は「かつ」、|は「または」
※drop_index(reset=True): indexを0から振りなおす
iloc
次にilocです。ilocはデータフレームの必要な情報のみをインデックスを基準として抜き取れます。
条件ひとつ

df7 = df.iloc[0, :]
df7
複数条件
.iloc[開始行:終了行-1, 開始列:終了列-1]
※終了の行or列を最後までしたい場合は「開始行or列:」のように後ろに数字を書かない
例).iloc[2:8, 1:3]

df8 = df.iloc[2:8, 1:3].reset_index(drop=True)
df8
※drop_index(reset=True): indexを0から振りなおす
後ろから数える
後ろから1番目は-1と数えることができます
これを利用して以下の範囲を抜き出します
iloc[2:, 3:-1]
df9 = df.iloc[2:, 3:-1].reset_index(drop=True)
df9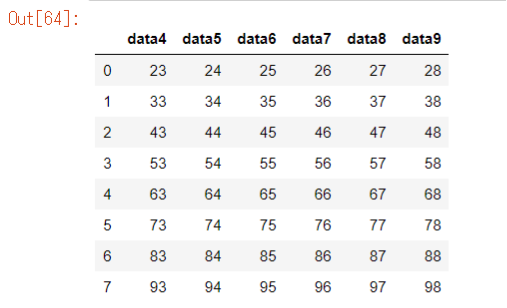
※drop_index(reset=True): indexを0から振りなおす
それでは🌏
最終更新日
2021/1/4
参考文献