【Python】OSを使って指定したファイル一覧を取得し、データフレームに読み込む!

はじめに
今回はos.listdirを用いて、ディレクトリ内にある(指定した)ファイルをリスト化する方法について説明します。
OSインターフェイスとは
osモジュールはオペレーティングシステムとやり取りする関数を何ダースか提供する:
(引用: Pythonチュートリアル第三版p115) osはコンピュータを操作を制御する基本的なソフトウェアのことで、今回の目的のファイル一覧の取得もこの機能を用います。
ファイル一覧を取得(os.listdir(path))
今回使用するディレクトリの階層性は以下のようにします。 (基本的にデータとコードが一緒のディレクトリに入れるとごちゃごちゃになるので、分けています) データは2021年1月1日~31日で、気温.txt・気温.xlsxの31日×2種類あります
└── current_dir
├── code.ipynb
└── atmos_data
├── 20210101_temperature.txt
⁝
├── 20210131_temperature.txt
├── 20210101_temperature.xlsx
⁝
└── 20210131_temperature.xlsx
それではまずはosモジュールをインポートして、データがあるディレクトリのファイルを全表示させてみます。
import os os.listdir("./atmos_data/")
['20210101_temperature.txt', '20210101_temperature.xlsx', '20210102_temperature.txt', ・・・・・・ '20210131_temperature.txt', '20210131_temperature.xlsx']
拡張子指定&データの種類指定
os.listdirを利用して、拡張子の指定ができます。方法は以下の通りです。
path = "./atmos_data/" dir_list = os.listdir(path) dir_list_temp = [x for x in dir_list if ".txt" in x] print(dir_list_temp)
['20210101_temperature.txt', '20210102_temperature.txt', '20210103_temperature.txt', ・・・・・・ '20210130_temperature.txt', '20210131_temperature.txt']
(1) dir_listに、ディレクトリ内の全ファイルをリストとして代入。
(dir_listには、.txtと.xlsxが混ざっている)
(2) dir_list_tempに、".txt"の拡張子を持つファイルのみを代入。
(dir_list_tempには、.txtのみが入っている)
取得したファイルの読み込み
まずはモジュールを読み込みます
import os import pandas as pd
pandasはデータフレームの処理に用います。
pandasについては、以下の記事を参照してください。
次に、指定ディレクトリ内の指定ファイル一覧をリスト化をします。
#指定ディレクトリ内の指定ファイル一覧をリスト化 path = "./atmos_data/" dir_list = os.listdir(path) dir_list_temp = [x for x in dir_list if ".txt" in x] print("LIST", dir_list_temp) #DataFrameの確認 df = pd.read_csv(path + dir_list_temp[0], index_col=0) #1つ目のファイルを使う print("DataFrame", df) df_cols = df.columns #1つ目のファイルのカラムをリストとして取得 print("COLUMNS", df_cols)
そして、dir_list_tempに代入したパスをディレクトリから読み込みます。
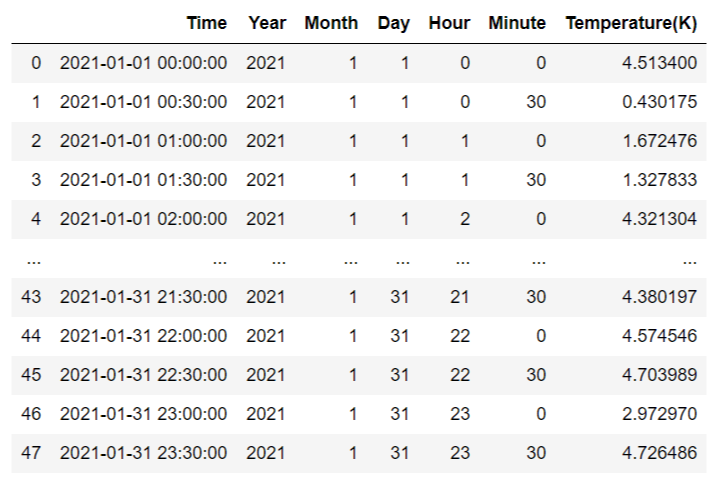
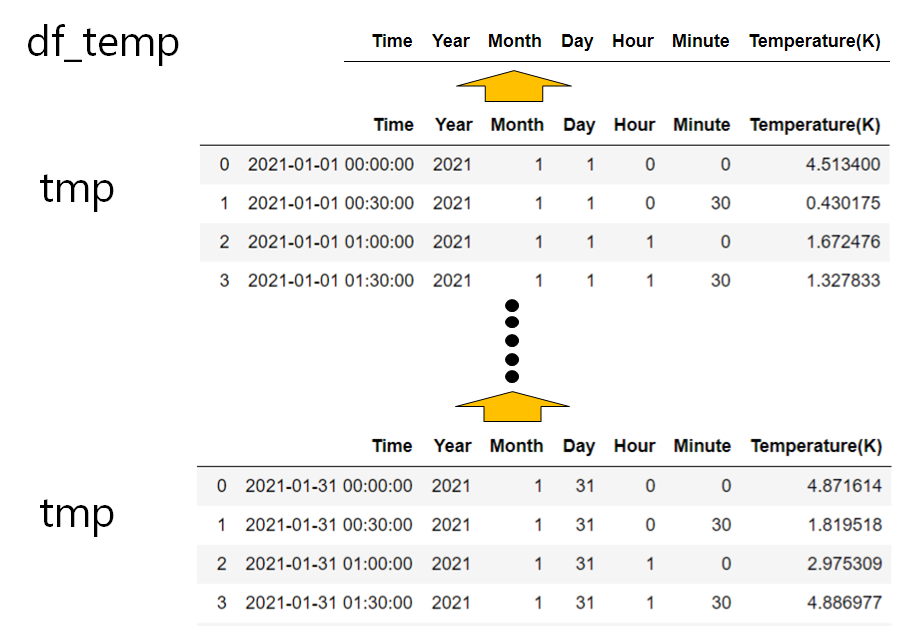
df_temp = pd.DataFrame(columns=df_cols) #空のdfを作成 for dir_list in dir_list_temp: tmp = pd.read_csv(path + dir_list, index_col=0) df_temp = pd.concat([df_temp, tmp], axis = 0) #縦方向に結合 df_temp
イメージ
(1)空のdfを用意する。この時、df_colsでカラムを設定する。
(2)dir_list_tempを1つずつ選択し、データを読み込み(tmp)、空のリストに縦方向に結合していく(pd.concat)(1/1~1/31)。
番外編: globを使う(拡張子指定)
import glob path = "./atmos_data/*.txt" list_dir = glob.glob(path) print(list_dir)
['./atmos_data\\20210101_temperature.txt', './atmos_data\\20210102_temperature.txt', './atmos_data\\20210103_temperature.txt', ・・・・・・ './atmos_data\\20210130_temperature.txt', './atmos_data\\20210131_temperature.txt']
参考文献
それでは🌏